
mysql随堂视频-索引
索引介绍及种类mysql视频 mysql索引
现实生活中使用目录来完成快速的查找。同理如果我们想快速的查找表里面的内容的话,我们就要使用类似于目录的东西,这个东西就称之为索引。
注:如果我们要对SQL进行优化,大部分都给别表添加索引。
索引工作过程:


这是一张员工表。现在我想查询名字是张三的这个人的信息:
select * from aa where name=’张三’;
在此表中找到张三需要几次查询?查找第一次的就找到了张三了。
找到张三之后还找吗?下面还是要继续找的,因为难免下面还有叫张三的人。要把整张表全部找一遍。
这样的找法我们称之为全表扫描。假如一张表有100万行,找的时间就比较久。

在这100w行数据里查找需要80毫秒,需要进行全表扫描。
为了快速查找,我可创建索引出来。

这里为name这列创建了索引,那么在索引文件里包含name列里所有的值,索引文件里的每个值都有一个指针,指向了数据文件里相对应的位置。然后对索引文件里的内容会根据某种算法来进行排序。
当我依据某个索引查找数据的时候,那么首先到索引里面查找,比如查找名字是张三的。
因为索引里已经排过序了,所以可以快速的在索引里查找到name,然后根据name=张三相对应的指针,就可以找到张三所有的数据。
因为在索引里查找到张三,那么索引后面就不会在出现张三了。
注:你使用哪列来做索引,那么这列所有的内容都是包保存在索引文件的。
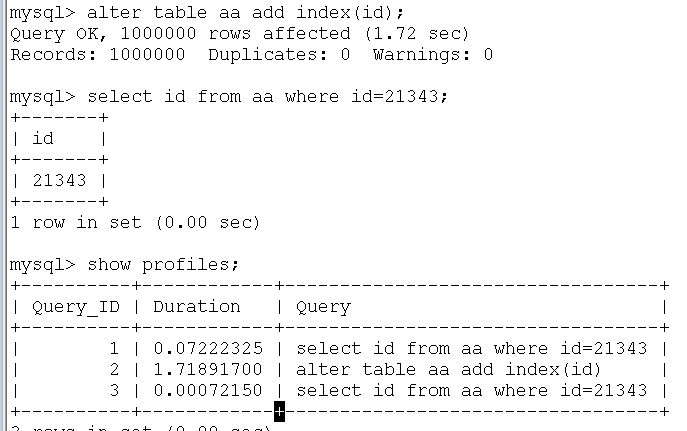
从这里可以看到有索引和没有索引的差距是100倍。
很多时候我们在测试索引是否正常工作(优化)的时候,更过使用的explain命令:
explain的用法:(explain也成为分析器)
explain select语句;
explain后面的语句并没有真正的执行,只是给我们分析了一下。

上图是使用索引的情况。

这条命令暂且删除索引:

上图type为all,就说明进行的是全文索引。涉及到了100w行。
明显能看出来使用索引比不使用索引速度要快了很多。因为在索引中能够快速的定位。
为什么能够在索引中快速的定位?
当我们把某列内容配置成索引的话,那么这列会拿到索引文件里面:

从上图可以看到索引文件比数据文件还要大。我们以id作为索引文件。
所有的id列的数据也保存一份在索引文件,并且进行排序:
在mysql默认使用的是平衡二叉树(BTREE)
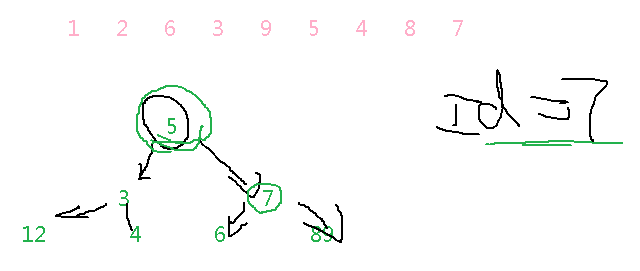
对于二叉树来说,左树总是小于右树的。
平衡二叉树:所谓的平衡二叉树指的是 左右两棵树不能相差两层。
假如一个索引里的数据已经平衡了,比如:
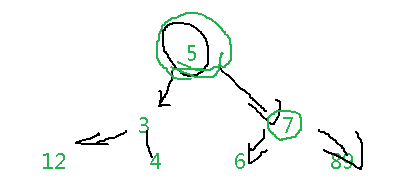
假如我现在插入两个数据,分别10和11

此时二叉树就变成这个样子了,现在还是平衡二叉树?所以此时索引会旋转这棵树。
索引有两个主要弊端:
1. 所占用的空间比较大
2. 当我们插入数据的时候,需要对索引做相应的更改,导致插入数据的速度比较慢。
所以建议:当大量更改数据的时候,先删除索引,等数据添加完了再创建索引。
