
k8s里,worker宕机后如何提高pod迁移速度
1-概念介绍
deployment控制器创建出来的副本会分布在不同的节点上,比如下图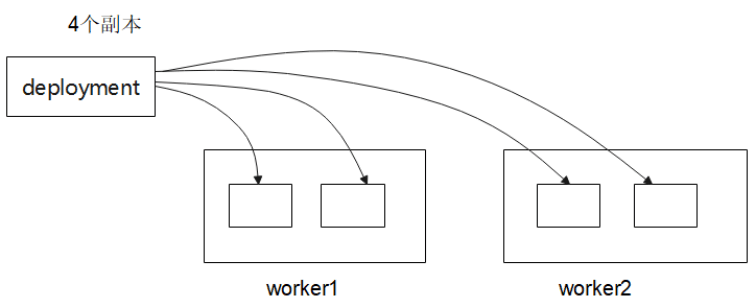

创建了一个deployment里面有4个副本,这4个副本分别运行在worker1和worker2上。
如果worker2宕机的话,那么worker2上的pod也不能正常工作了,对于deployment来说副本数缺失了两个,此时deployment会在有效节点上重新创建两个副本,以达到要求的4个副本。这样看起来就好像是worker2上运行的副本迁移到了worker1上了。
但是大家会发现,worker2上的pod迁移的速度会很慢,大概需要8~10分钟的时间,这是为何?如何提升迁移的速度呢?
这里我们先了解一下几个概念
kube-controller-manager--控制器管理器,内含很多控制器,比如
- 管理节点的控制器 node-controller
- 管理命名空间的控制器 namespace-controller
- 管理serviceaccount的控制器serviceAccount-controller
- 管理pod的控制器 deployment、daemonset、statefulset
所以节点的监控也是由controller-manager来管理的。
kubelet 自身会定期更新状态到 apiserver,通过kubelet的参数 node-status-update-frequency 配置上报频率,默认 10s 上报一次。
kube-controller-manager定期去探测kubelet的运行状态,就是kube-controller-manager每5s就问kubelet,"在不",kubelet就要回复"在",如果没回复controller-manager就会认为kubelet有问题了。多久不回复就会认为有问题呢?是由另外的一个参数决定的了。
这个参数就是node-monitor-grace-period,它必须是kubelet参数node-status-update-frequency的整数倍。当到达node-monitor-grace-period指定的时间,kubelet都没有回应,controller-manager就会认为kubelet有问题了。那么有问题又会怎么样呢?
有问题的话,那么这个节点就会设置污点
- node.kubernetes.io/unreachable:NoExecute
- node.kubernetes.io/unreachable:NoSchedule
然后运行在这个节点上的pod,还允许保留一段时间?这个是由kube-controller-manager的参数pod-eviction-timeout决定的,这个值默认是5分钟。
另外一个,现在节点被设置了污点,且pod还是在此节点上运行的。我们可以设置pod在有污点的节点上可以呆多久,那么就需要配置apiserver的参数default-unreachable-toleration-seconds决定的。
环境介绍
实验拓扑图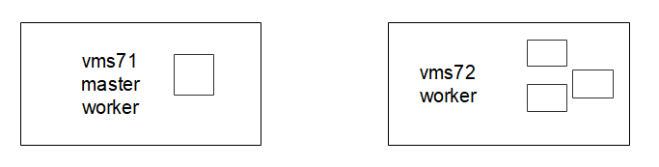
环境里共2台机器:
vms71:作为master,又作为worker
vms72:作为wokrer
后面创建的名字为web1的deployment有4个副本。
在/etc/kubernetes/manifests/kube-apiserver.yaml里添加参数
- --default-unreachable-toleration-seconds=5
在/etc/kubernetes/manifests/kube-controller-manager.yaml添加参数 - --node-monitor-period=5s
- --node-monitor-grace-period=20s
实验步骤
在15:16:42创建了一个deployment

通过命令date +%T ; kubectl describe nodes vms72.rhce.cc | grep -A5 Taint ; kubectl get pods -o wide ; kubectl get nodes vms72.rhce.cc查看时间、节点的污点情况、vms72的状态。
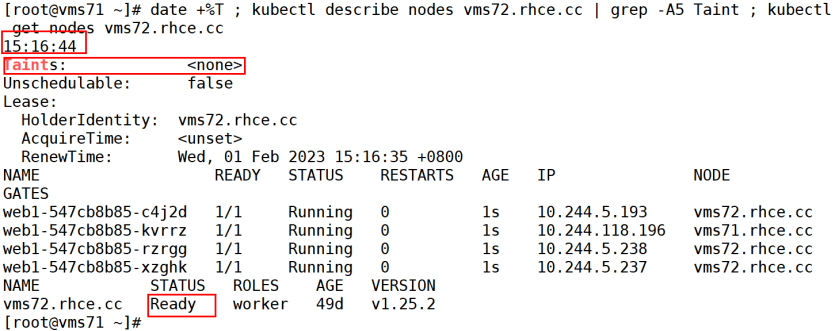
现在这里显示一切是正常的。
下面把vms72关机。
可以看到关机时间是15:16:51.
到15:17:08,离关机时间18s左右,查看主机状态,一切都是正常的(还没反应过来)。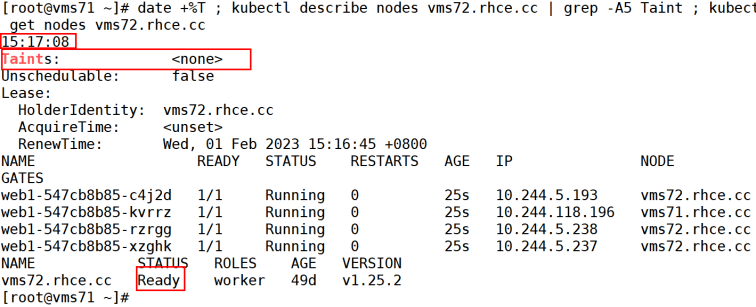
到15:17:09,离关机时间19s左右(大概20s),查看主机状态主机已经被设置为NotReady了,且添加了一个污点node.kubernetes.io/unreachable:NoSchedule。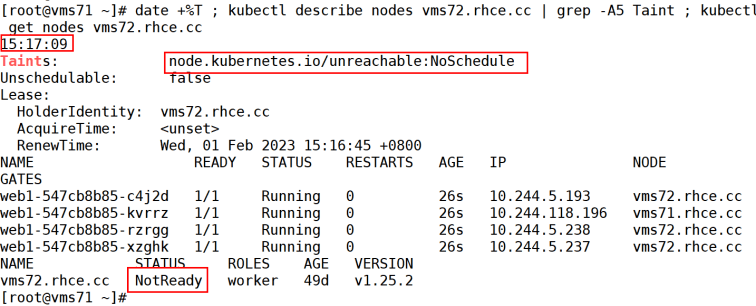
这里的这个20s是由kube-controller-manager参数--node-monitor-grace-period=20s决定的。
继续等,到了15:17:14的时候,vms72又被增加了一个节点node.kubernetes.io/unreachable:NoSchedule,如下图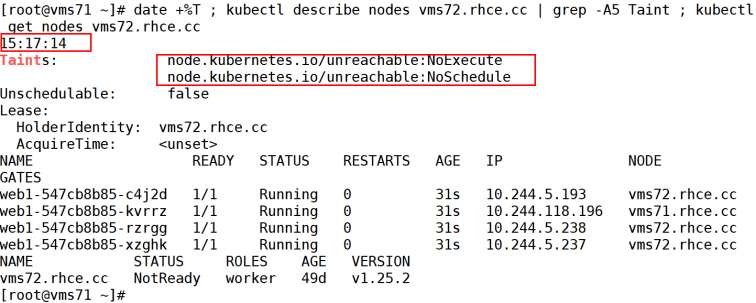
现在时间是15:17:14,节点已经被彻底标记为不可用了(NoExecute)。
然后在等一会到了15:17:20左右,分布到vms72删的pod已经被删除了,看下图。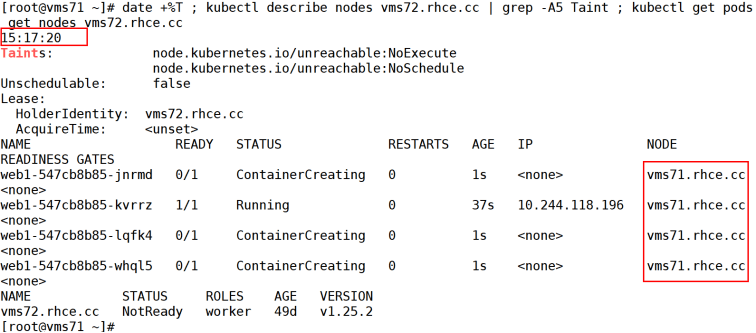
这离vms72彻底被标记为不可以用(15:17:14)大概是5,6秒的时间,这个时间有kube-apiserver的参数--default-unreachable-toleration-seconds=5决定的。
